平时我们写代码在html顶部总会加一条声明:
1 | <meta charset="UTF-8"> |
爬虫也总是会特别注意网页的编码格式,一个不小心就乱码了,今天学习廖雪峰大大的python教程中学习了一些有关字符编码的内容,本着举一反三的优良精神,所以特别的给自己加了餐。
最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以一个字节能标示的最大的整数就是255(二进制 11111111 = 十进制 255),如果要标示更大的整数,就必须用更多的字节,比如两个字节可以标示的最大整数是 65535等等。
最早计算机的美国人发明并给自己使用的,所以最早只有127个字符被编码到计算机里,也就是大小写英文字母以及数字和一些符号,这个编码表被称为ASXII 编码,比如大写的A的编码就是65。
但要处理中文显然一个字节是不够的,至少要两个字节,而且还不能和ASCII编码冲突,所以中国指定了GB2312编码,用来吧中文编进去,也就是一些小说网站常用的编码。
但仅仅有中文英文显然不够,全世界有上百中语言,日文的Shift_JIS,韩国的Euc-kr,各国有自己的语言以及标准,就不可避免的出现冲突,结果就是在多语言混合的文本中,显示出来会有乱码。
这时候,Unicode 编码格式就应运而生,Unicode 把所有的语言都统一到一套编码里,解决了各种标准的冲突问题。
但Unicode编码格式通常会占两个字节,而本来使用ASCII编码的文字只需要占一个字节,在过去网速以及内存都很小的时候显然每个字符占位更小一点对整体的大小会有很大影响,这个时候utf-8就再次应运而生了。
UTF-8 编码根据Unicode的字符的数字大小编码成1-6个字节,常用的英文字符编码成1个字节,汉子通常是3个字节,生僻字4-6个字节,可以节省很多空间。
所以在计算机中行成了如下两个通用的编码形式:
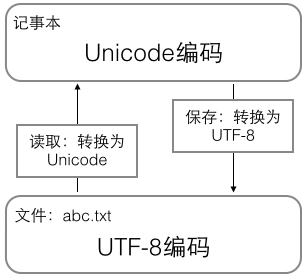
用记事本编辑的时候,从文件的读取的UTF-8字符被转换陈Unicode字符保存到内存里,编辑完成后保存的时候再把Unicode传唤为UTF-8保存到文件
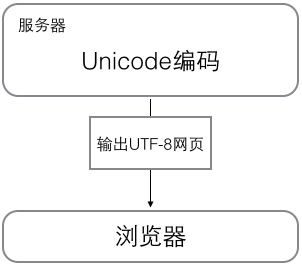
浏览网页的时候,服务器把动态生成的Unicode内容转换为UTF-8再传到浏览器: